




WordPress站长们,快给你的文章加上文字统计吧
编辑:狂族晨曦 来源:WordPress技巧 日期:2016-04-20 阅读: 3,729 次 4 条评论 » 百度已收录
先森闲着没事就爱逛逛张戈博客等WordPress大神们的博客,发现大神们的文章页面中,很多都加上了文字字数统计。不怎么起眼,但看到了会感觉很贴心。
百度了一下,发现代码基本上是来自知更鸟博客的,鸟叔确实厉害啊。先森体验了一把,代码部署起来非常简单,先将下面的代码放到functions.php里:
//字数统计
function count_words ($text) {
global $post;
if ( '' == $text ) {
$text = $post->post_content;
if (mb_strlen($output, 'UTF-8') < mb_strlen($text, 'UTF-8')) $output .= '本文共' . mb_strlen(preg_replace('/\s/','',html_entity_decode(strip_tags($post->post_content))),'UTF-8') . '个字';
return $output;}
}
然后在single.php中或其它希望显示字数统计的位置加上:
<?php echo count_words ($text); ?>
但是鸟叔也说了,中文统计没有什么问题,但英文统计的是字母。
英文按字母统计,也就意味着一个字母统计就会+1。而我们WordPress最多接触的就是代码,代码的字母动辄就是成百上千。一篇文章看着没有多少内容,字数统计却会显示几千字,看着着实有点不爽。
先森想要的效果是,中文按字数统计,英文按单词统计。先森特意看了下Word,发现Word就是这种统计规则。
但是令先森无奈的是,在各大搜索引擎搜了一遍,没有找到能够解决这个问题的教程。鸟叔虽然也分享了统计英文博客文字的代码,但是经先森测试,好像不会对本站的代码部分进行统计,总之就是统计出来的英文字数不对。想要中文代码统计文字时排除字母,再加上英文单词统计的想法破灭了~请看下面内容↓
不过先森在搜索的时候,另外发现了我爱水煮鱼关于如何统计中文字数研究的文章。文章介绍了PHP中,计算字符串长度的三种函数strlen,mb_strlen,mb_strwidth。水煮鱼用这三个函数去测试统计字符串的长度,看看它们分别把中文算成几个字节:
echo strlen("你好ABC") . "";
// 输出 9
echo mb_strlen("你好ABC", 'UTF-8') . "";
// 输出 5
echo mb_strwidth("你好ABC") . "";
// 输出 7
上面的测试显示:strlen 把中文字符算成 3 个字节,mb_strlen 不管中文还是英文,都算 1 个字节,而mb_strwidth 则把中文算成 2 个字节。而实际上,mb_strwidth 才是正确的:中文 2 个字节,英文 1 个字节。
现在再返回去看鸟叔提供的代码,统计的函数用的是第二种:mb_strlen。通过三种函数统计结果对比可知,这个函数是统计出来数字最少的一种。所以,在找到解决方法之前,鸟叔提供的代码已经是最好的解决方案了,将就着用吧。
先森之前一直搜索的是WordPress的方法,但后来通过搜索PHP的方法,找到了一些解决方案。
方案一:php 统计字数(支持中英文)的实现代码
首先还是在functions.php中添加下面代码;
//php 统计字数(支持中英文)的实现代码
function count_word($str){
$str = preg_replace('/[\x80-\xff]{1,3}/', ' ', $str,-1,$n);
$n += str_word_count($str);
return $n;
}
然后在希望显示字数统计的位置加上:
<?php echo ";本文共".count_word($post->post_content)."个字";?>
方案二:PHP统计中英文单词数(UTF-8编码)
注:这种方案不会统计标点符号。其实还有一种GB2312编码的方法,但据说无法统计中文,所以此处没提。
一样的,在functions.php中添加下面代码;
//PHP统计中英文单词数(UTF-8编码)
define( "UTF8_CHINESE_PATTERN", "/[\x{4e00}-\x{9fff}\x{f900}-\x{faff}]/u" );
define( "UTF8_SYMBOL_PATTERN", "/[\x{ff00}-\x{ffef}\x{2000}-\x{206F}]/u" );
// count only chinese words
function str_utf8_chinese_word_count($str = ""){
$str = preg_replace(UTF8_SYMBOL_PATTERN, "", $str);
return preg_match_all(UTF8_CHINESE_PATTERN, $str, $arr);
}
// count both chinese and english
function str_utf8_mix_word_count($str = ""){
$str = preg_replace(UTF8_SYMBOL_PATTERN, "", $str);
return str_utf8_chinese_word_count($str) + str_word_count(preg_replace(UTF8_CHINESE_PATTERN, "", $str));
}
也是一样的,在希望显示字数统计的位置加上:
<?php echo ";本文共".str_utf8_mix_word_count($post->post_content)."个字";?>
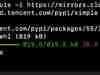
先森在测试的时候,发现不含代码,文字较多的文章,这两种方案统计除出来的数字会比鸟叔代码统计出来的多。下图中,第一个是鸟叔代码统计出的,第二个是方案一统计出的,第三个是方案二统计出的。可以看到,方案一和方案二都比鸟叔的多,方案一又比方案二多。为什么会比鸟叔代码统计的多先森没懂,但是方案一又比方案二多确实符合了方案二不统计标点符号的特性。

纯文字文章三种代码文字统计情况
而在存在代码的文章中,后面的两种方案统计出来的数字又会比鸟叔的小很多。

存在代码文章三种代码文字统计情况
总结
本文共分享了三种统计代码,要使用哪一种就根据各位自己的喜好来了。
正是因为先森没有搞明白方案一、二两种统计方式上面的那种情况到底是怎么回事,所以先森用的还是鸟叔的代码。
若有更合适的代码,还请网友告知。
转载请注明出处来自https://www.capjsj.cn/wpzcm_kgndwzjswztjb.html


 川公网安备 51011202000104号
川公网安备 51011202000104号
鸟叔。。哈哈!!人家有那么老吗?
@小C博客: 念着顺口了,就这么叫了
鸟叔,水叔,张叔,都是叔叔。
三种代码适合的人群不同吧,鸟大的适合那种不写代码的,,,