




用Linux分析日志查看产生大量404的IP
编辑:狂族晨曦 来源:系统运维,经验杂笔 日期:2016-05-12 阅读: 5,928 次 11 条评论 » 百度已收录
先森网站被阿里云通知超标消耗资源的时候查看网站的日志,发现有几个IP一直在访问一个不存在的目录,产生了大量的404。查了半天没有查出这些IP与先森使用的CDN等服务有关,看来不是什么好货了,赶紧用.htaccess屏蔽IP。
但是有个问题,日志文件是以行为记录,一行对应一个请求,一个日志经常成千上万行,光靠眼睛看不能准确的识别出这些做坏的IP到底有哪些。先森一直在找有没有能直接分析出来的日志分析工具,但搜到的都是针对搜索引擎蜘蛛痕迹做分析的,只得作罢。
近期先森在培训红帽Linux,经过学习,发觉Linux确实强大。而老师今天教了正则表达式,再加上以前教的各类命令,发现其实用Linux就能很好的做日志分析了。下面来分享下相关经验。
linux命令
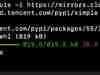
首先,查看日志,分析需要筛选的内容。先森贴出其中404的一例:
60.191.139.121 - - [09/May/2016:00:33:32 +0800] "GET /_detect HTTP/1.0" 404 209 "-" "-" qxu123456789.my3w.com text/html "/usr/home/qxu123456789/htdocs/_detect" 1048
需要注意的是,每行的状态码前后是有一个空格的,这个可以用来区分正常访问中单纯的404数字。
命令方面其实很简单,一句搞定:
# cat web.log| grep -E ' 404 '|awk '{print $1}'|sort |uniq
先森的日志回车后,最终显示了下面三个IP:
222.73.199.105 60.191.139.121 61.160.245.190
这样就确认了有哪些IP在对网站造成404访问了,这时候用.htaccess将其屏蔽即可。如果不会,可以参考先森这篇文章:
下面对上面的代码做些解释。
cat是将web.log的内容作为标准输出到设备,也就是查看文件内容。
|是管道符,将左边的输出连接到右边的输入,也就是把日志内容传给下一条命令。
gerp -E,相当于egerp,后面跟的是正则表达式,这里我们查找的内容比较简单,所以暂时不用正则表达式。这条命令用来筛选出有404的行。
awk是做数据处理的,是一种编程语言,功能很强大。它可以用-F确定分隔符,默认是空格,这也真是我们需要的。以空格为分隔符,将每行分成了很多段,而后面的printf $1就是输出第一段,也就是我们的IP地址。
sort是排序,这里就是对我们的IP地址进行排序。
uniq是去重,也就是将重复的IP地址去除,留下我们想要屏蔽的IP地址。
一些延伸
上面仅仅是找出404访问IP,实际上我们可能有这种需求:找去所有的40X的访问IP,修改上面的一个字符即可实现:
# cat web.log| grep -E ' 40. '|awk '{print $1}'|sort |uniq
.点符号在Linux正则表达式中是占位符,表示任意的一个字符。
有了上面的这种需求,可能我们除了想看IP地址,还想知道它的状态码是多少,再修改一下就好:
# cat web.log| grep -E ' 40. '|awk '{print $1,$9}'|sort |uniq
上面在awk的输出增加了一个$9,表示已空格作为分隔的第九段。其实想看什么数据,只要以空格为界,数出其所在段位即可。但需要注意的是,时间段不要用来数出,这样会导致后面的去重没有什么效果,因为时间都是不同的。

Linux操作
最后
不得不说Linux确实强大,但是它的英文也让先森很吃不消啊。希望能够学好,向着运维的方向越走越远。
转载请注明出处来自https://www.capjsj.cn/ylinuxfxrzckcsdl404dip.html


 川公网安备 51011202000104号
川公网安备 51011202000104号
评论了。怎么不出来?而且表情貌似不显示。
这个方法太666了!!
不知道要屏蔽这些IP做什么呢?
@Koolight: 因为会造成网站资源消耗啊,显示404页面也需要资源的嘛。先屏为敬!
linux好复杂的,还是win好
@精选故事网: 感觉Linux更好玩,嘿嘿
我也是用的阿里云。
@夏天烤洋芋: 感谢来访,阿里云还是造福了很多站长的
Linux我就玩不来,只能看看
Linux用着还是没有winds方便。个人感觉。