

标签:Linux
系统运维, 经验杂笔华为光猫HS8145V交叉编译静态tcpdump
先森是个网速强迫症,闲着没事就喜欢研究光猫、路由器那一套,还希望在任何地方只要有网就能控制家里的设备。可惜先森的电信光猫是大内网,双层NAT,没有ipv4公网IP,结果偶然先森发现家里设备都可以直连ipv6了,而且分配到设备的ipv6地址还是公网的,先森就想着使用ipv6来突破网络限制。结果,运营商为了保证安全,默认是限制了ipv6入访的。由于家里宽带不是先森办理的,先森不太方便直接将光猫改为桥接的模式,所幸是先森拿到了光猫超管密码,还可以通过shell的方式去操作iptables调整入访策略。但光猫的iptables策略特别多,先森也得为安全考虑,不能直接全放通,所以得进行测试。结果问题来了,光猫的shell中没有tcpdump的命令,没法抓包,让先森调试的心态爆炸,当时各种搜索都没有找到光猫抓包的方法。由于ipv6的支持在先森身边依旧不是那么普遍,像先森公司的商纤就没有分配ipv6(不知道是不是公司IT把ipv6分配给关了),腾讯云CDN回源也不支持ipv6源站,所以当时先森一条条iptables策略调试的差不多之后,也就搁置了。但是没法运行tcpdump抓包这个事一直让先森如鲠在喉,然后最近突然知道了“交叉编译”这么一个玩意儿,让先森沉寂的心死灰复燃。交叉编译:交叉编译是在一个平台上生成另一个平台上的可执行代码。如在x86平台上编译ARM平台上运行的可执行代码。先森在折腾的过程中遇到很多坑,在这里记录一下。配置情况光猫:华为HS8145V,已经开启telnet;交叉编译主机:CentOS 7.9 x86_64,其实应该用Ubuntu来交叉编译更方便,但是先森对这系统不熟。交叉编译器的寻找历程确认平台在网上搜交叉编译tcpdump的教程,一开始根本没注意到编译器,然后直接上手编译,这就跟平时正常编译一样,编译出来的是gcc编译的,根本不是交叉编译的。网上教程说要确认目标机是arm-linux还是mips-linux什么的,先森看光猫通过telnet登录的时候有什么BusyBox、Dopra Linux,搜了一圈也没能明确搜出来华为光猫的系统属于什么,只是搜到有说华为光猫使用的是海思芯片,属于arm架构的,最后是`uname -m`确认到华为这个是arm平台。选择arm-linux-gcc确认了光猫HS8145V是arm后,目标就很明确了,下载一下交叉编译器,然后开整。但先森万万没想到,arm-linux-gcc的下载链接那么难找,好不容易找到了,结果又发现arm-linux-gcc有很多版本,还要根据光猫arm的情况来选。arm-linux-gcc的不同版本那么光猫是什么情况呢,可以在命令行进行查看:WAP(Dopra Linux) # uname -aLinux EchoLife_WAP 3.10.53-HULK2 #1 SMP Fri Oct 20 01:08:58 CST 2017 armv7l GNU/Linux或者直接WAP(Dopra Linux) # uname -marmv7l实际在搜交叉编译的教程时,要不就是单纯的arm-linux-gcc,不然就是gcc-arm-linux-gnueabi和gcc-arm-linux-gnueabihf,所以就搜armv7l属于哪种。百度了半天,好像都说armV7属于armhf,想来armv7l应该也是,但实测不行,还得是armel。具体可以了解一下:arm-linux-gnueabi-gcc 和 arm-linux-gnueabihf-gcc:两个交叉编译器分别适用于 armel 和 armhf 两个不同的架构,armel 和 armhf 这两种架构在对待浮点运算采取了不同的策略(有 fpu 的 arm 才能支持这两种浮点运算策略)。其实这两个交叉编译器只不过是 gcc 的选项 -mfloat-abi 的默认值不同。gcc 的选项 -mfloat-abi 有三种值 soft、softfp、hard(其中后两者都要求arm 里有 fpu 浮点运算单元,soft 与后两者是兼容的,但 softfp 和 hard 两种模式互不兼容):soft: 不用fpu进行浮点计算,即使有fpu浮点运算单元也不用,而是使用软件模式。softfp: armel架构(对应的编译器为 arm-linux-gnueabi-gcc )采用的默认值,用fpu计算,但是传参数用普通寄存器传,这样中断的时候,只需要保存普通寄存器,中断负荷小,但是参数需要转换成浮点的再计算。hard: armhf架构(对应的编译器 arm-linux-gnueabihf-gcc )采用的默认值,用fpu计算,传参数也用fpu中的浮点寄存器传,省去了转换,性能最好,但是中断负荷高。下载arm-linux-gcc由于先森arm-linux-gcc的下载地址时比较痛苦,有点难找,所以显示把各种版本的链接在这里列一下。下载单纯的arm-linux-gcc,版本较老,4.4.3貌似是2010年发布的了资源地址:http://www.friendlyelec.com.cn/download.asp在页面中可以找到下载地址:http://112.124.9.243/arm9net/mini2440/linux/arm-linux-gcc-4.4.3-20100728.tar.gz下载arm-linux-gnueabi或arm-linux-gnueabihf,资源下载列表页是先选gcc版本,再选编译器架构,最后还要选架构运行平台,这里先森选的是最新版本latest-7中的arm-linux-gnueabi的64位系统版本。由于这个页面加载较慢或者未free无法打开,所以先森把两个版本的下载地址都贴出来:资源列表页:http://releases.linaro.org/components/toolchain/binaries/armel架构:http://124.156.146.205/gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabihf.tar.xzarmhf架构:http://124.156.146.205/gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabi.tar.xz配置arm-linux-gcc# 下载后解压tar -xJvf gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabi.tar.xz# 可选,先森是将其移动重命名了一下mv gcc-linaro-7.5.0-2019.12-x86_64_arm-linux-gnueabi /usr/local/arm# 可选,但建议操作cd /usr/local/arm/binln -s arm-linux-gnueabi-gcc arm-linux-gcc建议增加环境变量,不然编译的时候./configure的参数需要加上'CC=/usr/local/arm/bin'echo 'export PATH=$PATH:/usr/local/arm/bin' >> /etc/profilesource /etc/profile添加环境变量后,需要执行`arm-linux-gcc -v`测试一下arm-linux-gcc是否存在问题,可能会遇到下面的问题:bin/.arm-none-linux-gnueabi-gcc: /lib/ld-linux.so.2: bad ELF interpreter: No such file or directory# 解决方法:yum install -y ld-linux.so.2到这里终于把arm-linux-gcc部分弄完了,下面进入编译环节。交叉编译libpcap和tcpdump由于tcpdump需要依赖libpcap,所以需要下载这个包,分别编译,先森下载的最新版本:https://www.tcpdump.org/release/tcpdump-4.99.1.tar.gzhttps://www.tcpdump.org/release/libpcap-1.10.1.tar.gz交叉编译libpcap前面准备工作做好了,libpcap还是很好编译的。下载解压后,进入libpcap目录中:./configure --prefix=/tmp/armroot --host=arm-linux --target=arm-linux --with-pcap=linuxmakemake install# –prefix指定目标文件生成路径(makefile里面的target存放路径);# –host、–target都写成目标平台即可,例如:arm-liux或mips-linux,光猫是arm的,所以写arm-linux# --with-pcap将告诉编译器我们正在编译哪种数据包捕获类型# 如果前面没有加arm-linux-gcc的环境变量,那么需要加上CC='/usr/local/arm/bin'编译链路径编译时遇到的问题:# 问题1:configure: error: Neither flex nor lex was found.# 解决:yum install -y flex bison# 问题2:/usr/local/arm/bin/../libexec/gcc/arm-none-linux-gnueabi/4.4.3/cc1: error while loading shared libraries: libstdc++.so.6: cannot open shared object file: No such file or directory# 解决:貌似和系统是64位,gcc是32位有关,安装32位的库即可yum install -y libstdc++.i686# 问题3:/usr/local/arm/bin/../lib/gcc/arm-none-linux-gnueabi/4.4.3/../../../../arm-none-linux-gnueabi/bin/as: error while loading shared libraries: libz.so.1: cannot open shared object file: No such file or directory# 解决:yum -y install zlib.i686交叉编译tcpdump实际测试,tcpdump的交叉编译,必须是编译静态链接,编译器默认是动态链接库。由于光猫的根路径是只读的,而lib库就在系统路径中,无法在光猫添加确实的动态链接库文件,所以只能选择静态交叉编译这条路了。解压tcpdump包后,进入目录进行操作:# 指定静态交叉编译export CFLAGS=-staticexport CPPFLAGS=-staticexport LDFLAGS=-staticexport ac_cv_linux_vers=3./configure --prefix=/tmp/armroot --host=arm-linux --target=arm-linuxmakemake install# 编译好的文件就是当前目录下的tcpdump文件,也可以去--prefix执行的目录的bin或sbin目录找到tcpdump编译tcpdump时遇到的问题:# 问题1:configure: error: cannot determine linux version when cross-compiling# 解决办法:我们需要找出我们的 Ubuntu(或 Linux)操作系统内核正在运行的主要版本。执行 uname -a 命令。# 注意:您的输出可能会有所不同,但请查找类似于版本号的内容。下面,先森的主机是 3.10.0-1160.45.1.el7.x86_64,我们抓住第一个“3”。uname -aLinux VM-0-4-centos 3.10.0-1160.45.1.el7.x86_64 #1 SMP Wed Oct 13 17:20:51 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux# 然后将ac_cv_linux_vers 变量设置为上一个命令中发布的内核版本的主要编号,再尝试编译export ac_cv_linux_vers=3# 问题2:/mnt/jffs2/tcpdump: can't load library 'libc.so.6'# 解决:缺的动态链接库又没法塞进光猫的系统,所以需要静态交叉编译# 问题3:静态编译会遇到此类警告tcpdump.c:(.text+0x5a6): warning: Using 'initgroups' in statically linked applications requires at runtime the shared libraries from the glibc version used for linkin# 解决:正常现象,只是警告,不影响使用建议操作剥离符号信息,使二进制文件更小,这些符号仅在调试应用程序时有用,而光猫的存储容量比较小。[root@VM-0-4-centos bin]# ll -htotal 14M-rwxr-xr-x 1 root root 1.9K Apr 2 16:32 pcap-config-rwxr-xr-x 1 root root 6.9M Apr 2 16:33 tcpdump-rwxr-xr-x 1 root root 6.9M Apr 2 16:33 tcpdump.4.99.1[root@VM-0-4-centos bin]# arm-linux-gnueabi-strip tcpdump[root@VM-0-4-centos bin]# ll -htotal 8.4M-rwxr-xr-x 1 root root 1.9K Apr 2 16:32 pcap-config-rwxr-xr-x 1 root root 1.5M Apr 2 16:34 tcpdump-rwxr-xr-x 1 root root 6.9M Apr 2 16:33 tcpdump.4.99.1拿到光猫上去运行折腾了这么多,最终能在光猫上运行才是第一目标。先森是直接把tcpdump放到服务器的web目录中,然后光猫直接wget下载到光猫中的。先森在测试交叉编译的运行中,遇到了很多错误,总结下来是以下4种:# 第一种报错WAP(Dopra Linux) # ./tcpdump.Ullegal Illegal instruction# 第二种报错WAP(Dopra Linux) # ./tcpdump.libc /mnt/jffs2/tcpdump.libc: can't load library 'libc.so.6'# 第三种报错WAP(Dopra Linux) # ./tcpdump.0\:08 /mnt/jffs2/tcpdump.0:08: can't resolve symbol '__libc_start_main'# 第四种报错WAP(Dopra Linux) # ./android-tcpdump android-tcpdump: eth0: You don't have permission to capture on that device(socket: Operation not permitted)事实上,除了第四种,前三种都是编译有问题的版本,第四种只是提醒没有权限执行。没有权限的情况,经过一番搜索,先森找到了再次提权的方法(本来以为shell提权已经是终点了),二次提权只需要su切到root,密码:admin,可以通过whoami查看当前角色。二次提权后执行成功写在最后本来先森是想在文章最后把自己编译好的文件分享出来的,结果在完善本文的时候搜到了一篇Android官方写的tcpdump静态交叉编译的文档,其中有详细的静态编译步骤,也有官方编译好的文件下载地址。先森试了一下,直接下载Android官方编译的tcpdump也是能够在光猫运行的,如果先森一开始就搜到了这边文档或资源。。。。文档地址:https://www.androidtcpdump.com/android-tcpdump/compile直接下载:https://www.androidtcpdump.com/android-tcpdump/downloads
系统运维, 经验杂笔宝塔php如何安装ldap扩展
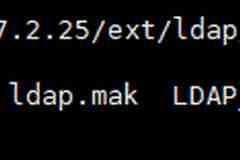
今天打算在服务器上部署一个zabbix,做一些日常监控,结果在配置网页的时候,遇到了一点问题。zabbix安装缺少ldap扩展既然缺少,那就安装咯(当然,ldap扩展不是必须的,也可以忽略它继续下一步)。安装ldap扩展在网上看到的教程都是先编译php,再安装ldap扩展。可是先森这边已经使用宝塔安装好了php,所以看他们的教程看的晕晕乎乎的,不过所幸还是折腾好了。第一步,下载php源码宝塔的php扩展文件夹里是没有ldap的,所以我们需要去下载一个php完整的源码包,将里面的ldap盘出来。下载源码包的时候,需要与你宝塔已经安装的大版本匹配。先森安装的是7.2的php,所以要去官网下载7.2版本的源码,小版本就不用管了,先森下载的是7.2.25版本。在哪里下载?如果是7.2版本及更新的版本,可以直接在https://www.php.net/downloads.php如果是7.2版本以前的老版本,那就在旧档案里面下载吧:https://www.php.net/releases/电脑下载可能会比较慢,毕竟源站在国外,一般来说用服务器下载会快一些。第二步,编译ldap下载完毕php源码包之后,解压而入之,扩展文件夹是'ext',再入之,可见'ldap'。cd ./php-7.2.25/ext/ldap/进入ldap源文件目录然后就可以开始编译了。/www/server/php/72/bin/phpize #准备扩展库的编译环境./configure --with-php-config=/www/server/php/72/bin/php-config #编译配置make && make install #编译安装ls /www/server/php/72/lib/php/extensions/no-debug-non-zts-20170718/ # 查看编译好的ldap.so文件编译与查看成果第三步,修改配置文件下面需要把ldap加到php.ini里面,添加的方式有两种。php --ini #查看php.ini的位置:Configuration File (php.ini) Path: /www/server/php/72/etcLoaded Configuration File: /www/server/php/72/etc/php.ini第一种,取消php.ini原本的注释将';extension=ldap'前面的引号删除后重启php-fpm即可。删除注释第二种,在末尾新增配置[ldap]extension = ldap.so新增配置第四步,重启php添加配置后重启php-fpm即可,可以命令行重启,也可以在宝塔界面。service php-fpm-72 restart #重启php重启后再在zabbix界面查看就可以发现所有检查都通过了。检测通过
系统运维, 经验杂笔CentOS搭建lsyncd实时同步——取代rsync+inotify
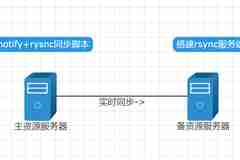
昨天先森发布了“CentOS下inotify+rsync实现文件实时同步”,inotify+rsync实时同步的方案是用shell在后台常驻来实现实时同步,没有守护进程,感觉不是很靠谱,如果脚本突然挂了,实时同步岂不是GG了?所以先森在实现了inotify+rsync后还是再找其他的解决方案。其实在找到lsyncd之前,先森先找到了sersync这个工具,但是好像这个工具很久没有更新了,所以虽然也有较多好评,但是先森目前还是先研究lsyncd了。当然,无论是sersync还是lsyncd,其实都是对inotify这个内核中的文件事件监控系统进行了封装,类似inotify-tools,给我们提供的是封装好了的inotify+rsync工具。sersync是用C写的,lsyncd是使用lua语言封装的。搭建lsyncd实时同步lsyncdlsyncd项目也托管在GitHub上面,具体地址是https://github.com/axkibe/lsyncd,一会儿若是要编译安装也需要去这个地方。上文也说过,lsyncd是使用lua语言封装的,所以初识lsyncd的配置文件时,还是有点不习惯,但是用久应该就还好了。lsyncd不仅仅是实现两台服务器的同步的,它还能够在一台服务器内对两个文件夹进行同步,这里可以是cp,也可以是rsync。两台或多台服务器间可以是rsync,也可以是rsyncssh。本文主要讲的是两台服务器间的rsync。lsyncd可以配置inotify检测到文件变动后多少秒才执行同步,也就是时间延迟。也可以配置文件变动个数达到多少个后立即执行同步,无论有没有到达前面的时间延迟的要求,这就是累计触发事件次数。这两个配置可以减少rsync的同步,避免海量文件同步时rsync的频繁发送文件对比列表。lsyncd安装lsyncd的安装方式有两种,yum安装和编译安装。yum安装:yum安装也有两种方式,一个是阿里云的镜像源,一个是fedoraproject的镜像源。阿里云:#CentOS 7wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo#CentOS 6wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo#yum 安装yum install lsyncd -yfedoraproject:#只找到CentOS 6的rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpmyum install lsyncd -y编译安装:1、首先还是去上文提到的GitHub上下载项目,通过下面的下载就是最新的了:wget https://github.com/axkibe/lsyncd/archive/master.zip2、下载了软件包,先别急着安装,上文提到了几次,lsyncd是用lua语言封装的,所以还需要安装lua环境。另外lsyncd不是使用的make,而是cmake,所以也需要安装cmake。yum install -y lua lua-devel asciidoc cmake3、下载了软件包,装好了环境依赖,下面就是编译安装:unzip lsyncd-master.zipcd lsyncd-mastercmake -DCMAKE_INSTALL_PREFIX=/usr/local/lsyncdmake && make install安装好了的lsyncd在/usr/local/lsyncd下。配置文件、日志文件夹等需要我们自己定义与创建。4、配置文件。先森的配置文件是用于两台服务器间实时同步的,使用的是rsync模式。lsyncd的配置文件其实有点类似nginx,如nginx的server可以多定义互不冲突一样,lsyncd也可以多个定义。settings { logfile ="/usr/local/lsyncd/logs/lsyncd.log", statusFile ="/usr/local/lsyncd/logs/lsyncd.status", inotifyMode = "CloseWrite or Modify", maxProcesses = 15, }sync { default.rsync, source = "/web/data/ftp", target = "user@172.17.8.16::datahome", delete="running", exclude = { ".*", ".tmp","*.swp","*.swx" }, delay = 0, rsync = { binary = "/usr/bin/rsync", archive = true, compress = true, verbose = true, password_file = "/etc/rsyncd/rsync.passwd", } }注释版:settings { --定义日志文件 logfile ="/usr/local/lsyncd/logs/lsyncd.log", --定义状态文件 statusFile ="/usr/local/lsyncd/logs/lsyncd.status", --指定inotify监控的事件,默认是CloseWrite,还可以是Modify或CloseWrite or Modify --这个就是使用的inotify能监控的事件 inotifyMode = "CloseWrite or Modify", --同步进程的最大个数。假如同时有20个文件需要同步,而maxProcesses = 8,则最大能看到有8个rysnc进程 maxProcesses = 15, --(这个配置先森没有使用)累计到多少所监控的事件激活一次同步,即使后面的delay延迟时间还未到。 --maxDelays=10, }sync { --使用rsync通过daemon方式连接远程rsyncd进程; default.rsync, --同步的源目录,使用绝对路径。 source = "/web/data/ftp", --定义目的地址,对应不同的模式有不同的写法。这里是远程rsync,使用“用户名@ip::模块名”写法。 target = "user@172.17.8.16::datahome", --是否同步删除,除了running选项,还有true、false和startup,这个配置先森不是很明白,大概是true是完全同步删除,false是不允许删除,startup和running要难理解一些\ --先森的理解是,startup是仅在启动时将源目录和目的目录来一次完全同步,lsyncd运行时的源目录的删除文件在目的目录中不做删除操作\ --running是启动时不对源、目的目录进行完全同步,lsyncd运行时源目录删除的文件,目的目录也会被删除。 delete="running", --排除的文件,这里排除了一些隐藏文件,和文件打开是时的临时文件 exclude = { ".*", ".tmp","*.swp","*.swx" }, -- 累计事件,等待rsync同步延时时间,默认15秒。先森配置的是0,也就是实时同步。 delay = 0, rsync = { --本地rsync命令路径 binary = "/usr/bin/rsync", archive = true, compress = true, verbose = true, --远程rsyncd的密码 password_file = "/etc/rsyncd/rsync.passwd", } }5、启动lsyncd/usr/local/lsyncd/bin/lsyncd -log Exec /usr/local/lsyncd/lsyncd.conf也可以自己创建一个启动脚本,脚本内容如下,是先森从yum安装的lsyncd拷贝的,一样的可以使用。只是用之前,需要对lsyncd守护命令与配置文件先做个软连接,免得需要修改启动脚本:ln -s /usr/local/lsyncd/bin/lsyncd /usr/bin/lsyncdln -s /usr/local/lsyncd/lsyncd.conf /etc/lsyncd.conf启动脚本:#!/bin/bash## chkconfig: - 85 15# description: Lightweight inotify based sync daemon## processname: lsyncd# config: /etc/lsyncd.conf# config: /etc/sysconfig/lsyncd# pidfile: /var/run/lsyncd.pid# Source function library. /etc/init.d/functions# Source networking configuration.. /etc/sysconfig/network# Check that networking is up.[ "$NETWORKING" = "no" ] && exit 0LSYNCD_OPTIONS="-pidfile /var/run/lsyncd.pid /etc/lsyncd.conf"if [ -e /etc/sysconfig/lsyncd ]; then . /etc/sysconfig/lsyncdfiRETVAL=0prog="lsyncd"thelock=/var/lock/subsys/lsyncdstart() { [ -f /etc/lsyncd.conf ] || exit 6 echo -n $"Starting $prog: " if [ $UID -ne 0 ]; then RETVAL=1 failure else daemon ${LSYNCD_USER:+--user ${LSYNCD_USER}} /usr/bin/lsyncd $LSYNCD_OPTIONS RETVAL=$? [ $RETVAL -eq 0 ] && touch $thelock fi; echo return $RETVAL}stop() { echo -n $"Stopping $prog: " if [ $UID -ne 0 ]; then RETVAL=1 failure else killproc lsyncd RETVAL=$? [ $RETVAL -eq 0 ] && rm -f $thelock fi; echo return $RETVAL}reload(){ echo -n $"Reloading $prog: " killproc lsyncd -HUP RETVAL=$? echo return $RETVAL}restart(){ stop start}condrestart(){ [ -e $thelock ] && restart return 0}case "$1" in start) start ;; stop) stop ;; restart) restart ;; reload) reload ;; condrestart) condrestart ;; status) status lsyncd RETVAL=$? ;; *) echo $"Usage: $0 {start|stop|status|restart|condrestart|reload}" RETVAL=1esacexit $RETVAL优化因为lsyncd其实也是用到了inotify,所以和inotify+rsync方案一样,我们还是需要对服务器的inotify内核配置进行优化。inotify检查磁盘变动是有队列等值的配置的,inotify默认内核参数值太小,会导致实际检测的时候报错。查看系统默认参数值sysctl -a | grep max_queued_eventssysctl -a | grep max_user_watchessysctl -a | grep max_user_instances临时修改sysctl -w fs.inotify.max_queued_events="99999999"sysctl -w fs.inotify.max_user_watches="99999999"sysctl -w fs.inotify.max_user_instances="65535"固定修改:vim /etc/sysctl.conf #添加以下代码fs.inotify.max_queued_events=99999999fs.inotify.max_user_watches=99999999fs.inotify.max_user_instances=65535其他官方配置文件wiki:https://axkibe.github.io/lsyncd/manual/config/file/
脚本编程, 系统运维, 经验杂笔CentOS下inotify+rsync实现文件实时同步
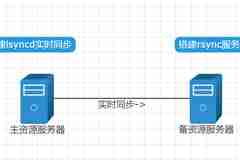
rsync仅同步差异文件,所以传输效率较高,所以先森在项目中负载的资源服务器做了rsync同步,确保通过负载IP都能访问到相同的文件,使用crontab计划任务每1分钟执行一次同步。计划任务最小时间刻度为1分钟(虽然可以用数学方法再调小,但是运行密度大了对服务器会造成负荷),也就是上传一张图片,最长可能要等1分钟后才能在其它服务器上访问,如果同步目录下的文件基数是百万级的,那么时间可能更久。这种方案先森曾发过:CentOS下rsync服务器安装与配置-数据同步|文件增量备份inotify+rsync实时同步rsync的不足rsync具有安全性高、备份迅速、支持增量备份等优点,通过rsync可以解决实时性不高的数据备份需求,例如定期数据库备份。但随着业务规模的扩大,业务需求的增加,rsync的缺点也暴露出来了:1、当文件数量大到百万级别,rsync仅差异扫描就是一项非常耗时的工作;2、rsync自身不能实时的检测并同步数据,它总是被动的通过各种方式去触发同步。inotify与inotify-tools注:inotify是一个 Linux 内核特性,inotify-tools是为linux下inotify文件监控工具提供的一套C的开发接口库函数。inotify:inotify是一种强大的、细粒度的、异步的文件系统事件监控机制,Linux内核从2.6.13开始引入,允许监控程序打开一个独立文件描述符,并针对事件集监控一个或者多个文件,例如打开、关闭、移动/重命名、删除、创建或者改变属性。CentOS 6是已经支持的了,判断服务器是否支持inotify,只需要执行下面命令,查看是否有结果即可。ll /proc/sys/fs/inotifyinotify-tools:inotify-tools是为linux下inotify文件监控工具提供的一套C的开发接口库函数,同时还提供了一系列的命令行工具,这些工具可以用来监控文件系统的事件。inotify-tools是用c编写的,除了要求内核支持inotify外,不依赖于其他。inotify-tools提供两种工具,一是inotifywait,它是用来监控文件或目录的变化,二是inotifywatch,它是用来统计文件系统访问的次数。我们主要用到的是inotifywait工具。inotify-tools安装inotify-tools先森找到了两种安装方式,rpm安装和编译安装,先森用的是编译安装。rpm安装wget http://dl.fedoraproject.org/pub/epel/6/x86_64/Packages/i/inotify-tools-3.14-1.el6.x86_64.rpmrpm -vhi inotify-tools-3.14-1.el6.x86_64.rpm编译安装编译前请确保服务器已安装编译组件:yum install -y make gcc gcc-c++这个项目是发布在github上的,下载也是在github上下载。但是先森在项目首页下载下来的无法编译安装,所以安装的还是3.1.4版本的。github项目地址:https://github.com/rvoicilas/inotify-tools/编译安装:wget http://github.com/downloads/rvoicilas/inotify-tools/inotify-tools-3.14.tar.gztar zxvf inotify-tools-3.14.tar.gzcd inotify-tools-3.14./configure #或./configure --prefix=/usr/local/inotifymakemake install安装后命令在/usr/local/bin/目录下。查看效果:/usr/local/bin/inotifywait -mrq --format '%Xe %w%f' -e modify,create,delete,attrib /data/不停止上面的命令,新建终端连接然后进入/data/文件夹进行各类操作,可以看下上面输出的结果。rsync组合inotify-tools完成实时同步inotify的作用,是让我们知道监控的文件夹中有变动,我们可以根据inotify输出内容,去触发rsync同步。提示:以往使用crontab触发rsync时,我们是将rsync服务端搭建在主服务器,其他服务器去主服务器同步文件。而inotify+rsync的方式,是将rsync服务端搭建在从服务器,主服务器推送文件到从服务器,所以从服务器上的rsync配置中“read only”要配置为no,也就是“read only = no”。inotify-tools只是个工具,并不是软件,所以要与rsync配合就需要我们自己写shell脚本,并让脚本一直运行在后台。先森通过实际测试,整理出了两个脚本,也就是两种方案。方案1:#!/bin/bashsource /etc/profilesrc=/data/ # 需要同步的源路径des=datahome # 目标服务器上 rsync 模块名rsync_passwd_file=/etc/rsyncd/rsync.passwd # rsync验证的密码文件ipaddr=(10.0.0.1) # 目标服务器,多个目标服务器以空格分开user=user # rsync --daemon定义的验证用户名logs=/var/log/inotify_rsync.logs # 日志inotify_rsync(){cd ${src} # 此方法中,由于rsync同步的特性,这里必须要先cd到源目录,inotify再监听 ./ 才能rsync同步后目录结构一致,有兴趣的同学可以进行各种尝试观看其效果/usr/local/bin/inotifywait -mrq --format '%Xe %w%f' -e modify,create,delete,attrib,close_write,move --exclude=".*.swp" ./ | while read file # 把监控到有发生更改的"文件路径列表"循环do INO_EVENT=$(echo $file | awk '{print $1}') # 把inotify输出切割 把事件类型部分赋值给INO_EVENT INO_FILE=$(echo $file | awk '{print $2}') # 把inotify输出切割 把文件路径部分赋值给INO_FILE echo "-------------------------------$(date)------------------------------------" echo $file #增加、修改、写入完成、移动进事件 #增、改放在同一个判断,因为他们都肯定是针对文件的操作,即使是新建目录,要同步的也只是一个空目录,不会影响速度。 if [[ $INO_EVENT =~ 'CREATE' ]] || [[ $INO_EVENT =~ 'MODIFY' ]] || [[ $INO_EVENT =~ 'CLOSE_WRITE' ]] || [[ $INO_EVENT =~ 'MOVED_TO' ]] # 判断事件类型 then echo 'CREATE or MODIFY or CLOSE_WRITE or MOVED_TO' for ip in ${ipaddr[@]} do rsync -avzcR --password-file=${rsync_passwd_file} --exclude="*.swp" --exclude="*.swx" $(dirname ${INO_FILE}) ${user}@${ip}::${des} >> $logs # INO_FILE变量代表路径哦 -c校验文件内容 done #仔细看 上面的rsync同步命令 源是用了$(dirname ${INO_FILE})变量 即每次只针对性的同步发生改变的文件的目录(只同步目标文件的方法在生产环境的某些极端环境下会漏文件 现在可以在不漏文件下也有不错的速度 做到平衡) 然后用-R参数把源的目录结构递归到目标后面 保证目录结构一致性 fi #删除、移动出事件 if [[ $INO_EVENT =~ 'DELETE' ]] || [[ $INO_EVENT =~ 'MOVED_FROM' ]] then echo 'DELETE or MOVED_FROM' echo 'CREATE or MODIFY or CLOSE_WRITE or MOVED_TO' for ip in ${ipaddr[@]} do rsync -avzR --delete --password-file=${rsync_passwd_file} --exclude="*.swp" --exclude="*.swx" $(dirname ${INO_FILE}) ${user}@${ip}::${des} >> $logs done #看rsync命令 如果直接同步已删除的路径${INO_FILE}会报no such or directory错误 所以这里同步的源是被删文件或目录的上一级路径,并加上--delete来删除目标上有而源中没有的文件,这里不能做到指定文件删除,如果删除的路径越靠近根,则同步的目录月多,同步删除的操作就越花时间。这里有更好方法的同学,欢迎交流。 fi #修改属性事件 指 touch chgrp chmod chown等操作 if [[ $INO_EVENT =~ 'ATTRIB' ]] then echo 'ATTRIB' if [ ! -d "$INO_FILE" ] # 如果修改属性的是目录 则不同步,因为同步目录会发生递归扫描,等此目录下的文件发生同步时,rsync会顺带更新此目录。 then for ip in ${ipaddr[@]} do rsync -avzcR --password-file=${rsync_passwd_file} --exclude="*.swp" --exclude="*.swx" $(dirname ${INO_FILE}) ${user}@${ip}::${des} >> $logs done fi fidoneinotify_rsync >> $logs 2>&1}inotify_rsync >> $logs 2>&1将上面内容保存为inotify_rsync_A.sh,执行:inotify_rsync_A.sh &或使用screen后台启动。另外,为避免意外遗漏文件,最好在定时任务中每隔两个小时执行一次全目录同步。这个方案的优点:利用inotify让rsync每次仅同步有更改的文件,减少递归操作。缺点:经过先森实际运用发现,inotify的特性,每次创建文件会产生多条输出,而这个脚本inotify的每条输出都会触发一次rsync,这样会对服务器资源产生浪费。方案2:为了解决方案1的问题,先森找到了另一个脚本,对方案1的脚本进行了修改:#!/bin/bashsource /etc/profilesrc=/data/ # 需要同步的源路径des=datahome # 目标服务器上 rsync 模块名rsync_passwd_file=/etc/rsyncd/rsync.passwd # rsync验证的密码文件ipaddr=(10.0.0.1) # 目标服务器,多个目标服务器以空格分开user=user # rsync --daemon定义的验证用户名inlogs=/var/log/inotifywait.logslogs=/var/log/inotify_rsync.logserrlog=/var/log/inotify_rsync.err.logscd ${src} # 此方法中,由于rsync同步的特性,这里必须要先cd到源目录,inotify再监听 ./ 才能rsync同步后目录结构一致,有兴趣的同学可以进行各种尝试观看其效果/usr/local/bin/inotifywait -mrq --format '%Xe %w%f' -e modify,create,delete,attrib,close_write,move --exclude=".*.swp" ./ >> $inlogs &while true;do if [ -s ${inlogs} ];then grep -i -E "delete|moved_from" ${inlogs} >> /var/log/inotify_away.log for ip in ${ipaddr[@]} do rsync -avzcR --password-file=${rsync_passwd_file} --exclude="*.swp" --exclude="*.swx" ${src} ${user}@${ip}::${des} >> $logs RETVAL=$? done #同步失败后的输出日志 if [ $RETVAL -ne 0 ];then echo "${src} sync to ${ipaddr} failed at `date +"%F %T"`,please check it by manual" >> $errlog fi cat /dev/null > $inlogs for ip in ${ipaddr[@]} do rsync -avzcR --password-file=${rsync_passwd_file} --exclude="*.swp" --exclude="*.swx" ${src} ${user}@${ip}::${des} >> $logs done else sleep 1 fidone这个脚本是将inotify的检测内容输出到文件/var/log/inotifywait.logs,脚本判断这个文件是否为空,非空则表明有变动,那么就来一次完整的同步。如果文件为空则睡眠1秒。将上面内容保存为inotify_rsync_B.sh,执行:inotify_rsync_B.sh &这个方案的优点:不会根据inotify输出重复触发rsync同步。缺点:每次都是rsync完整同步,如果文件数量较大则对比时间会比较长。inotify优化inotify检查磁盘变动是有队列等值的配置的,inotify默认内核参数值太小,会导致实际检测的时候报错。查看系统默认参数值sysctl -a | grep max_queued_eventssysctl -a | grep max_user_watchessysctl -a | grep max_user_instances临时修改sysctl -w fs.inotify.max_queued_events="99999999"sysctl -w fs.inotify.max_user_watches="99999999"sysctl -w fs.inotify.max_user_instances="65535"固定修改:vim /etc/sysctl.conf #添加以下代码fs.inotify.max_queued_events=99999999fs.inotify.max_user_watches=99999999fs.inotify.max_user_instances=65535

脚本编程, 系统运维, WordPress技巧新版Linux/vps本地十五天循环备份和七牛远程备份脚本
最新在新建一个博客,新的博客是建在云服务器的,完全自主,不得不说感觉非常好,比起虚拟主机可操作性强太多了。因为可操作性强,所以想把该做的都做好,比如备份。受张戈博客影响,看到了张戈的同步7天的那篇文章,想照着操作的时候发现,七牛的qrsync工具竟已废弃:qrsync已废弃看这简介,推荐使用qshell命令行工具,先森就干脆研究下使用新的工具来同步。有段时间没和七牛云储存打交道了,变化还是挺大的。为七牛的推陈出新点个赞。一、数据库、网站本地备份脚本在服务器上编辑shell脚本,脚本代码如下:#!/bin/bash# Name:liuxxbak.sh# This is a ShellScript For Auto Backup and Delete old Backup# Date:2017-8-19source /etc/profilebackupdir=/web/data/liuxx_bak # 本地备份路径time=` date +%Y%m%d `date=` date +"%Y-%m-%d %H:%M:%S" `day=15 #本地备份保留天数# 数据库信息user=rootpassword=******host=127.0.0.1port=3306databases=wordpress# 本地网站根目录backhome=/web/data/html/if [ ! -d $backupdir ]; then mkdir $backupdirfi mysqldump -h $host -P $post -u $user -p$password ${data} | gzip > $backupdir/${data}_$time.sql.gzif [ "$?" == 0 ];then echo "[${date}] 数据库 ${data} 备份成功!!" >> ${backupdir}/mysqllog.logelse#备份失败则进行以下操作 echo "[${date}] 数据库 ${data} 备份失败!!" >> ${backupdir}/mysqllog.logfi# 备份网站tar -zcvf $backupdir/liuxx_${time}.tar.gz $backhome > /dev/null 2>&1# 删除同步find $backupdir -name "*.gz" -type f -mtime +${day} -exec rm {} \; > /dev/null 2>&1先森将以上代码保存为‘liuxxbak.sh’,名称可以随意自定义。保存后需要增加可执行权限:chmod +x liuxxbak.sh使用说明:将以上内容变量按需修改:backupdir=本地备份绝对路径day=本地备份保留天数user=数据库用户名(建议使用root用户,出错可能性小)password=数据库密码host=数据库IP或域名port=数据库端口databases=数据库名称backhome=本地网站根目录脚本执行方式:./liuxxbak.sh或者/web/data/liuxxbak.sh # 绝对路径执行如此可以检查一下是否能够成功备份。二、远程备份到七牛云储存1.命令。首先下载qshell命令行工具,下载页面:根据服务器类型选择下载linux 64位的服务器可以直接在服务器上这样下载并增加可执行权限:wget -O qshell http://devtools.qiniu.com/2.1.3/qshell-linux-x64 && chmod +x qshell可以将qshell命令放入自定义目录。或直接放至/usr/bin/路径下,这样就可以任何地方直接输入命令了。2.鉴权。有了命令之后,我们需要七牛的鉴权,否则没法使用接下来的命令。需要鉴权的命令都需要依赖七牛账号下的 AccessKey 和 SecretKey。所以这类命令运行之前,需要使用 account 命令来设置下 AccessKey ,SecretKey 。鉴权的方式很简单,首先进入七牛的个人中心->密钥管理中,找到AccessKey 和 SecretKey。然后在服务器中运行一下命令:/web/data/qshell account ak sk执行之后,用户的所有信息写入到磁盘$HOME_DIR/.qshell下面。如:root用户执行后,信息会保存在/root/.qshell/account.json文件中。如果你修改了密钥,只需要重新执行以上命令即可,配置信息将被覆盖。3.同步。终于到了这一步。qshell命令的命令有很多,同步需要用到的命令是qupload。qupload是用来将本地目录中的文件同步到七牛空间中的命令。命令格式:qshell qupload [<ThreadCount>] <LocalUploadConfig>ThreadCount:并发上传的协程数量,默认为1,即文件一个个上传,对于大量小文件来说,可以通过提高该参数值来提升同步速度。LocalUploadConfig:数据同步的配置文件,该配置文件里面包含了一些诸如本地同步目录,目标空间名称等信息。ThreadCount是可以忽略的参数,默认一个文件一个文件的上传,因为是要备份数据库和本地网站文件,文件较少且大,顾保持默认就好。LocalUploadConfig为配置文件,配置文件中可带的参数共有21个,先森选用了其中的7个。详细的配置介绍请看这里。先森选用的参数如下,将以下内容保存到文件‘localupload.cnf’:{ "src_dir" : "/web/data/liuxx_bak", "bucket" : "liuxx-backup", "ignore_dir" : true, "overwrite" : true, "check_exists" : true, "check_hash" : true, "rescan_local" : true}解释,*为必须项:"src_dir":"/web/data/liuxx_bak", # 本地备份路径*"bucket":"liuxx-backup", #同步数据的目标空间名称,可以为公开空间或私有空间*"ignore_dir":true, #远程同步到七牛时,忽略本地路径"overwrite":true, #覆盖同名文件"check_exists":true, #上传前检查是否有同名文件"check_hash":true, #在check_exists设置为true的情况下生效,是否检查本地文件hash和空间文件hash一致"rescan_local":true, #检测本地新增文件并同步最后,远程同步到七牛云储存的命令为:/web/data/qshell qupload /web/data/localupload.cnf可以执行一下上面的命令,检查是否能够成功同步。先森同步到七牛云的效果:同步效果三、定时备份同步准备工作已经完毕了,现在所需的就是每天的自动备份及远程备份了。执行crontab -e添加以下内容:00 02 * * * /web/data/liuxxbak.sh30 02 * * * /web/data/qshell qupload /web/data/localupload.cnf >/dev/null 2>&1凌晨两点执行本地备份,凌晨两点半执行远程备份。当然,你也可以将qshell命令加到liuxxbak.sh脚本的最后,那么只用添加第一条计划任务就可以了。四、七牛十五天循环备份七牛云储存免费的存储空间大小是10G,如果你的七牛云存储空间有点紧急的话,可以继续本操作。这时候,点击‘生命周期’,添加规则,我们可以设定删除15天前的文件。先森设定的规则如下:删除15天前的文件当然,如果七牛云存储的剩余空间很足的话,可以保留更多天,这样可供回退的版本就更多了。总结无论是用虚拟主机,还是使用云服务器,有一套备份的机制是很重要的。如果像先森一样,主站使用的是虚拟主机,也有另外的云服务器的话,这套备份方案改改,也可以把自己虚拟主机的数据库一起备份起来嘛。
系统运维, 经验杂笔溯源:mysql导入导出文件报错ERROR 1290 (HY000):–secure-file-priv
近期遇到mysql导出文件的错误,之前遇到这个错误,因为需要导出的数据少,所以直接将结果手动复制。mysql> select * from childrenzone_order into outfile '/tmp/test.txt' fields terminated by ',' optionally enclosed by '"' escaped by '"' lines terminated by '\r\n';ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement但后来遇到大量的数据需要导出,简单的复制就不能满足需求了。进行百度,发现解决方法很简单,在配置文件里增加配置,重启Mysql即可。只是,生产环境中,数据库是不能随意重启的,所以这个问题就很麻烦了。为了避免往后出现这种问题,先森觉得有必要研究清楚这个问题究竟影响了多少Mysql。解决方法首先是解决此类问题的方法,通过secure_file_priv 来完成对导入|导出的限制。secure_file_priv是在 /etc/my.cnf 中的[mysqld]下配置,共有三种限制方式。1、限制mysqld 不允许导入 | 导出:secure_file_priv = null2、限制mysqld 的导入 | 导出 只能发生在指定目录下,如/tmp目录:secure_file_priv = /tmp3、不对mysqld 的导入 | 导出做限制,有两种书写方式:secure_file_priv = /或secure_file_priv =而查询secure_file_priv的方式如下:mysql> show variables like '%secure%';查询secure_file_priv变量配置secure_file_priv变量配置的默认值为“NULL”,也就是默认不允许导入导出。溯源虽然知道了解决方法,但是前文也提到过,生产环境的Mysql并不能随意的重启,即使有主备。所以,弄明白受到默认禁止导入导出的Mysql版本有哪些就有必要了。通过查询官方文档,先森找到了影响版本,见下图(点击放大)。官方文档变量介绍通过上图可以看到,最后一个被红框框选的文字:“Before MySQL 5.5.53, this variable is empty by default.(在MySQL 5.5.53,这个变量默认是空的。)”。这个变量在Mysql 5.5.53之后新增了“NULL”的配置,且默认为“NULL”。所以,如果发现自己的Mysql版本是5.5.53以后的,且不想限制导入导出的话,最好把变量的值配置好后择时重启Mysql。另外,上图还介绍了,secure_file_priv这个变量是全局变量,且不能动态修改。这也是必须写入配置文件并重启Mysql的原因。

脚本编程, 系统运维, 经验杂笔Linux:sed的命令中插入变量的方法
先森近期接到个任务,这个任务中一项是需要每个服务器都得有自己的主机名,而不是默认的“localhost”。因为是CentOS 6的操作系统,所以需要改的文件有两个,且为了不用重启才生效,还要用hostname这个命令指定主机名。hostname命令用于显示和设置系统的主机名称。环境变量HOSTNAME也保存了当前的主机名。在使用hostname命令设置主机名后,系统并不会永久保存新的主机名,重新启动机器之后还是原来的主机名。如果需要永久修改主机名,需要同时修改/etc/hosts和/etc/sysconfig/network的相关内容。如果每台服务器都去手动修改这两个文件和执行hostname命令未免太过麻烦,所以先森写了一个简单的脚本。想用“./脚本名 主机名”的方式修改主机名,但是实现脚本的过程中发生了一点小问题。hostname=$1sed -i 's/HOSTNAME=.*/HOSTNAME=$hostname/g' /etc/sysconfig/network先森想用sed命令用指定的变量值来替换“HOSTNAME=”后面指定的值,但执行后发现,等号后面的值变成了$符号+变量名称,也就是sed命令中不认这个变量。后来经过百度一番,找到了答案:“因为 hostname 是shell变量而不是sed中的变量,需要单独拿到 sed 的单引号外面来才能被 shell 解析。单引号里面是 sed 的势力范围,shell 无法触及。”sed的参数后的命令,是已单引号开始,单引号结束的,所以想将shell变量拿出来,那就在变量前面加个单引号让sed命令结束,再在变量后面再加个单引号让sed命令再开始,已就是这样:hostname=$1sed -i 's/HOSTNAME=.*/HOSTNAME='$hostname'/g' /etc/sysconfig/network感觉这种代码的编辑模式很眼熟,一下就想到了在HTML里面写PHP的样子:<?php if (is_home()){ ?> </body> <?php } ?>写脚本突然有点写PHP的感觉,着实让先森觉得有点新鲜。下面贴下修改CentOS 6系统的主机名脚本。#!/bin/bash[ $# != 1 ] && echo "请指定主机名:./hostname.sh 主机名" && exit 1hostname=$1echo 127.0.0.1 ${hostname} >> /etc/hostssed -i 's/HOSTNAME=.*/HOSTNAME='$hostname'/g' /etc/sysconfig/networkhostname ${hostname}hostname.sh

系统运维, 经验杂笔原来TCP 协议可以这样容易懂
在运维工作中,经常接触到网络,所以先森今天看到这篇文章觉得写得不错,转载过来自用。一、TCP 协议的作用互联网由一整套协议构成。TCP 只是其中的一层,有着自己的分工。(图片说明:TCP 是以太网协议和 IP 协议的上层协议,也是应用层协议的下层协议。)最底层的以太网协议(Ethernet)规定了电子信号如何组成数据包(packet),解决了子网内部的点对点通信。(图片说明:以太网协议解决了局域网的点对点通信。)但是,以太网协议不能解决多个局域网如何互通,这由 IP 协议解决。(图片说明:IP 协议可以连接多个局域网。)IP 协议定义了一套自己的地址规则,称为 IP 地址。它实现了路由功能,允许某个局域网的 A 主机,向另一个局域网的 B 主机发送消息。(图片说明:路由器就是基于 IP 协议。局域网之间要靠路由器连接。)路由的原理很简单。市场上所有的路由器,背后都有很多网口,要接入多根网线。路由器内部有一张路由表,规定了 A 段 IP 地址走出口一,B 段地址走出口二,......通过这套"指路牌",实现了数据包的转发。(图片说明:本机的路由表注明了不同 IP 目的地的数据包,要发送到哪一个网口(interface)。)IP 协议只是一个地址协议,并不保证数据包的完整。如果路由器丢包(比如缓存满了,新进来的数据包就会丢失),就需要发现丢了哪一个包,以及如何重新发送这个包。这就要依靠 TCP 协议。简单说,TCP 协议的作用是,保证数据通信的完整性和可靠性,防止丢包。二、TCP 数据包的大小以太网数据包(packet)的大小是固定的,最初是1518字节,后来增加到1522字节。其中, 1500 字节是负载(payload),22字节是头信息(head)。IP 数据包在以太网数据包的负载里面,它也有自己的头信息,最少需要20字节,所以 IP 数据包的负载最多为1480字节。(图片说明:IP 数据包在以太网数据包里面,TCP 数据包在 IP 数据包里面。)TCP 数据包在 IP 数据包的负载里面。它的头信息最少也需要20字节,因此 TCP 数据包的最大负载是 1480 - 20 = 1460 字节。由于 IP 和 TCP 协议往往有额外的头信息,所以 TCP 负载实际为1400字节左右。因此,一条1500字节的信息需要两个 TCP 数据包。HTTP/2 协议的一大改进, 就是压缩 HTTP 协议的头信息,使得一个 HTTP 请求可以放在一个 TCP 数据包里面,而不是分成多个,这样就提高了速度。(图片说明:以太网数据包的负载是1500字节,TCP 数据包的负载在1400字节左右。)三、TCP 数据包的编号(SEQ)一个包1400字节,那么一次性发送大量数据,就必须分成多个包。比如,一个 10MB 的文件,需要发送7100多个包。发送的时候,TCP 协议为每个包编号(sequence number,简称 SEQ),以便接收的一方按照顺序还原。万一发生丢包,也可以知道丢失的是哪一个包。第一个包的编号是一个随机数。为了便于理解,这里就把它称为1号包。假定这个包的负载长度是100字节,那么可以推算出下一个包的编号应该是101。这就是说,每个数据包都可以得到两个编号:自身的编号,以及下一个包的编号。接收方由此知道,应该按照什么顺序将它们还原成原始文件。(图片说明:当前包的编号是45943,下一个数据包的编号是46183,由此可知,这个包的负载是240字节。)四、TCP 数据包的组装收到 TCP 数据包以后,组装还原是操作系统完成的。应用程序不会直接处理 TCP 数据包。对于应用程序来说,不用关心数据通信的细节。除非线路异常,收到的总是完整的数据。应用程序需要的数据放在 TCP 数据包里面,有自己的格式(比如 HTTP 协议)。TCP 并没有提供任何机制,表示原始文件的大小,这由应用层的协议来规定。比如,HTTP 协议就有一个头信息Content-Length,表示信息体的大小。对于操作系统来说,就是持续地接收 TCP 数据包,将它们按照顺序组装好,一个包都不少。操作系统不会去处理 TCP 数据包里面的数据。一旦组装好 TCP 数据包,就把它们转交给应用程序。TCP 数据包里面有一个端口(port)参数,就是用来指定转交给监听该端口的应用程序。(图片说明:系统根据 TCP 数据包里面的端口,将组装好的数据转交给相应的应用程序。上图中,21端口是 FTP 服务器,25端口是 SMTP 服务,80端口是 Web 服务器。)应用程序收到组装好的原始数据,以浏览器为例,就会根据 HTTP 协议的Content-Length字段正确读出一段段的数据。这也意味着,一次 TCP 通信可以包括多个 HTTP 通信。五、慢启动和 ACK服务器发送数据包,当然越快越好,最好一次性全发出去。但是,发得太快,就有可能丢包。带宽小、路由器过热、缓存溢出等许多因素都会导致丢包。线路不好的话,发得越快,丢得越多。最理想的状态是,在线路允许的情况下,达到最高速率。但是我们怎么知道,对方线路的理想速率是多少呢?答案就是慢慢试。TCP 协议为了做到效率与可靠性的统一,设计了一个慢启动(slow start)机制。开始的时候,发送得较慢,然后根据丢包的情况,调整速率:如果不丢包,就加快发送速度;如果丢包,就降低发送速度。Linux 内核里面设定了(常量TCP_INIT_CWND),刚开始通信的时候,发送方一次性发送10个数据包,即"发送窗口"的大小为10。然后停下来,等待接收方的确认,再继续发送。默认情况下,接收方每收到两个TCP 数据包,就要发送一个确认消息。"确认"的英语是 acknowledgement,所以这个确认消息就简称 ACK。ACK 携带两个信息:·期待要收到下一个数据包的编号·接收方的接收窗口的剩余容量发送方有了这两个信息,再加上自己已经发出的数据包的最新编号,就会推测出接收方大概的接收速度,从而降低或增加发送速率。这被称为"发送窗口",这个窗口的大小是可变的。(图片点击放大)(图片说明:每个 ACK 都带有下一个数据包的编号,以及接收窗口的剩余容量。双方都会发送 ACK。)注意,由于 TCP 通信是双向的,所以双方都需要发送 ACK。两方的窗口大小,很可能是不一样的。而且 ACK 只是很简单的几个字段,通常与数据合并在一个数据包里面发送。(图片说明:上图一共4次通信。第一次通信,A 主机发给B 主机的数据包编号是1,长度是100字节,因此第二次通信 B 主机的 ACK 编号是 1 + 100 = 101,第三次通信 A 主机的数据包编号也是 101。同理,第二次通信 B 主机发给 A 主机的数据包编号是1,长度是200字节,因此第三次通信 A 主机的 ACK 是201,第四次通信 B 主机的数据包编号也是201。)即使对于带宽很大、线路很好的连接,TCP 也总是从10个数据包开始慢慢试,过了一段时间以后,才达到最高的传输速率。这就是 TCP 的慢启动。六、数据包的遗失处理TCP 协议可以保证数据通信的完整性,这是怎么做到的?前面说过,每一个数据包都带有下一个数据包的编号。如果下一个数据包没有收到,那么 ACK 的编号就不会发生变化。举例来说,现在收到了4号包,但是没有收到5号包。ACK 就会记录,期待收到5号包。过了一段时间,5号包收到了,那么下一轮 ACK 会更新编号。如果5号包还是没收到,但是收到了6号包或7号包,那么 ACK 里面的编号不会变化,总是显示5号包。这会导致大量重复内容的 ACK。如果发送方发现收到三个连续的重复 ACK,或者超时了还没有收到任何 ACK,就会确认丢包,即5号包遗失了,从而再次发送这个包。通过这种机制,TCP 保证了不会有数据包丢失。(图片说明:Host B 没有收到100号数据包,会连续发出相同的 ACK,触发 Host A 重发100号数据包。)(完)

系统运维, 经验杂笔CentOS 7中的Nginx控制脚本
先森安装Nginx都是编译安装,所以不像yum安装的自带控制脚本,也就是不能通过service nignx start这种方式启动Nginx。不过在CentOS 6中,Nginx的启动脚本早已备好,增加控制脚本轻轻松松。不过,先森公司的客户要求新的服务器全用CentOS 7的操作系统,如此一来,先森之前的控制脚本就没用了。虽然先森当初培训的时候学习的就是RedHat 7,但是参加工作以来,一直使用的CentOS 6的操作系统,早已把7版本的命令习惯忘完。先森觉得,CentOS 6和CentOS 7的变化最明显的就是控制服务启动关闭的命令,由service换成了systemctl。虽然在CentOS 7中service命令依旧可以用,但是使用的效果已经大打折扣了。在网上找了半天,想要找到与CentOS 6类似的控制脚本,用service启动的,但是效果差强人意,甚至可以说无效。最后终于找到了使用systemctl的控制脚本,下面分享一波。控制脚本第一步:编辑vim /usr/lib/systemd/system/nginx.service文件,添加以下内容:注意要修改nginx的目录,先森的是放在默认的/usr/local/nginx中。[Unit]Description=nginx - high performance web serverDocumentation=http://nginx.org/en/docs/After=network.target remote-fs.target nss-lookup.target[Service]Type=forkingPIDFile=/usr/local/nginx/logs/nginx.pidExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.confExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.confExecReload=/bin/kill -s HUP $MAINPIDExecStop=/bin/kill -s QUIT $MAINPIDPrivateTmp=true[Install]WantedBy=multi-user.target第二步:添加可执行权限:chmod 755 /usr/lib/systemd/system/nginx.service第三步:添加开机启动:systemctl enable nginx控制Nginx:systemctl start nginx # 启动Nginxsystemctl stop nginx # 关闭Nginxsystemctl status nginx # 查看Nginx状态总结唉,CentOS 7咋用咋不习惯,但是系统版本的升级总是大势所趋,还是得慢慢习惯。运维的路,还很长。
系统运维, 经验杂笔解决VMware Workstation桥接模式无法联网问题
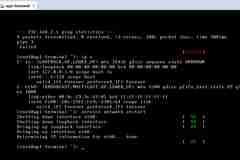
因为工作原因,先森经常会用到虚拟机做测试,然而也经常遇到桥接模式没有办法联网,无法获取IP地址的问题。以往先森的做法都是重启VMware Workstation甚至重启物理机,但这些往往都很误事,所以先森决定好好找找问题原因,幸运的是,先森找到了问题所在。桥接模式获取不到IP解决问题问题如上图,重启网络会在获取IP那一步等待很久(DHCP),然后报错,查看IP可以看到eth0没有IP地址。这种情况的原因可能是由于桥接模式桥接的网卡不正确,解决步骤如下。第一步,VMware中点击“编辑”->“虚拟网络编辑器”;虚拟网络编辑器第二步VMware默认的桥接模式中桥接方式为“自动”,而自动,可能就将网络桥接到其他网卡上去了,所以造成无法联网。这时候第二步就是把桥接到的网卡选择为物理机上网的网卡。点击电脑右下角的网络,再点击“打开网络和共享中心”,打开后选择“更改适配器设置”。在连接网络的适配器下面有网卡的名称,如先森的是“本地连接”下的“Realtek PCIe GBE Family Controller”。这时候就将VMware的桥接模式桥接到“Realtek PCIe GBE Family Controller”这个网卡,点击确认保存即可。更改桥接网卡设置第三步这时候再重启网络,即可获取到IP地址。网络恢复正常
 川公网安备 51011202000104号
川公网安备 51011202000104号